Коэффициент парной корреляции в Excel. Корреляционно-регрессионный анализ в Excel: инструкция выполнения
Количественная характеристика взаимосвязи может быть получена при вычислении коэффициента корреляции.
Корреляционный анализ в Excel
Сама функция имеет общий вид КОРРЕЛ(массив1;массив2). В поле «Массив1» вводим координаты диапазона ячеек одного из значений, зависимость которого следует определить. Как видим, коэффициент корреляции в виде числа появляется в заранее выбранной нами ячейке. Открывается окно с параметрами корреляционного анализа. В отличие от предыдущего способа, в поле «Входной интервал» мы вводим интервал не каждого столбца отдельно, а всех столбцов, которые участвуют в анализе. Как видим, приложение Эксель предлагает сразу два способа корреляционного анализа.
График корреляции в excel
6) В левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Поэтому гипотеза Н0 отклоняется, то есть параметры регрессии и коэффициент корреляции не случайно отличаются от нуля, а статистически значимы. 7. Полученные оценки уравнения регрессии позволяют использовать его для прогноза.
Как рассчитать коэффициент корреляции в Excel
Если коэффициент равен 0, это говорит о том, что взаимосвязь между значениями отсутствует. Чтобы найти взаимосвязь между переменными и у, воспользуйтесь встроенной функцией Microsoft Excel «КОРРЕЛ». Например, для «Массив1» выделите значения у, а для «Массив2» выделите значения х. В итоге вы получите рассчитанный программой коэффициент корреляции. Далее необходимо вычислить разницу между каждым x и xср, и yср. В выбранных ячейках напишите формулы x-x, y-. Не забудьте закрепить ячейки со средними значениями. Полученный результат и будет искомым коэффициентом корреляции.
Приведенная выше формула расчета коэффициента Пирсона, показывает насколько трудоемок этот процесс если выполнять его вручную. Второе, порекомендуйте, пожалуйста, какой вид корреляционного анализа можно использовать для разных выборок с большим разбросом данных? Как мне статистически доказать достоверность отличий между группой старше 60 лет и всеми остальными?
Сделай сам: вычисление корреляций валют с использованием Excel
Мы, к примеру, используем Microsoft Excel, но подойдёт и любая другая программа, в которой можно использовать корреляционную формулу. 7.После этого выделите ячейки с данными по EUR/USD. 9.Нажмите Enter для того, чтобы высчитать коэффициент корреляции для EUR/USD и USD/JPY. Обновлять цифры каждый день не стоит (ну, разве что вы одержимы корреляциями валюты).
Вы уже сталкивались с необходимостью рассчитать степень связи двух статистических величин и определить формулу, по которой они коррелируют? Для этого я воспользовался функцией CORREL (КОРРЕЛ) — о ней есть немного информации здесь. Она возвращает степень корреляции двух диапазонов данных. Теоретически, функцию корреляции можно уточнить, если перевести ее из линейной в экспоненциальную или логарифмическую. Анализ данных и графиков корреляции позволяет улучшить ее достоверность очень существенно.
Предположим, в ячейке В2 находится сам коэффициент корреляции, в ячейке В3 — количество полных наблюдений. У Вас русскоязычный офис?Кстати, нашел и ошибку — значимость не вычисляется для отрицательных корреляций. Если обе переменные метрические и имеют нормальное распределение, то выбор сделан правильно. И, можно ли, характеризовать критерий схожести кривых лишь по одному КК?У Вас не схожесть «кривых», а схожесть двух рядов, которая в принципе может описываться кривой.
Заметьте! Решение вашей конкретной задачи будет выглядеть аналогично данному примеру, включая все таблицы и поясняющие тексты, представленные ниже, но с учетом ваших исходных данных…Задача:
Имеется связанная выборка из 26 пар значений (х k
,y k
):
| k | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| x k | 25.20000 | 26.40000 | 26.00000 | 25.80000 | 24.90000 | 25.70000 | 25.70000 | 25.70000 | 26.10000 | 25.80000 |
| y k | 30.80000 | 29.40000 | 30.20000 | 30.50000 | 31.40000 | 30.30000 | 30.40000 | 30.50000 | 29.90000 | 30.40000 |
| k | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| x k | 25.90000 | 26.20000 | 25.60000 | 25.40000 | 26.60000 | 26.20000 | 26.00000 | 22.10000 | 25.90000 | 25.80000 |
| y k | 30.30000 | 30.50000 | 30.60000 | 31.00000 | 29.60000 | 30.40000 | 30.70000 | 31.60000 | 30.50000 | 30.60000 |
| k | 21 | 22 | 23 | 24 | 25 | 26 |
| x k | 25.90000 | 26.30000 | 26.10000 | 26.00000 | 26.40000 | 25.80000 |
| y k | 30.70000 | 30.10000 | 30.60000 | 30.50000 | 30.70000 | 30.80000 |
Требуется вычислить/построить:
- коэффициент корреляции;
- проверить гипотезу зависимости случайных величин X и Y, при уровне значимости α
= 0.05 ;
- коэффициенты уравнения линейной регрессии;
- диаграмму рассеяния (корреляционное поле) и график линии регрессии;
РЕШЕНИЕ:
1. Вычисляем коэффициент корреляции.
Коэффициент корреляции - это показатель взаимного вероятностного влияния двух случайных величин. Коэффициент корреляции R может принимать значения от -1 до +1 . Если абсолютное значение находится ближе к 1 , то это свидетельство сильной связи между величинами, а если ближе к 0 - то, это говорит о слабой связи или ее отсутствии. Если абсолютное значение R равно единице, то можно говорить о функциональной связи между величинами, то есть одну величину можно выразить через другую посредством математической функции.
Вычислить коэффициент корреляции можно по следующим формулам:
| n |
| Σ |
| k = 1 |
| M x | = |
|
| x k , | M y | = | или по формуле
На практике, для вычисления коэффициента корреляции чаще используется формула (1.4) т.к. она требует меньше вычислений. Однако если предварительно была вычислена ковариация cov(X,Y) , то выгоднее использовать формулу (1.1), т.к. кроме собственно значения ковариации можно воспользоваться и результатами промежуточных вычислений. 1.1 Вычислим коэффициент корреляции по формуле (1.4) , для этого вычислим значения x k 2 , y k 2 и x k y k и занесем их в таблицу 1. Таблица 1
1.2. Вычислим M x по формуле (1.5) . 1.2.1. x k x 1 + x 2 + … + x 26 = 25.20000 + 26.40000 + ... + 25.80000 = 669.500000 1.2.2. 669.50000 / 26 = 25.75000 M x = 25.750000 1.3. Аналогичным образом вычислим M y . 1.3.1. Сложим последовательно все элементы y k y 1 + y 2 + … + y 26 = 30.80000 + 29.40000 + ... + 30.80000 = 793.000000 1.3.2. Разделим полученную сумму на число элементов выборки 793.00000 / 26 = 30.50000 M y = 30.500000 1.4. Аналогичным образом вычислим M xy . 1.4.1. Сложим последовательно все элементы 6-го столбца таблицы 1 776.16000 + 776.16000 + ... + 794.64000 = 20412.830000 1.4.2. Разделим полученную сумму на число элементов 20412.83000 / 26 = 785.10885 M xy = 785.108846 1.5. Вычислим значение S x 2 по формуле (1.6.) . 1.5.1. Сложим последовательно все элементы 4-го столбца таблицы 1 635.04000 + 696.96000 + ... + 665.64000 = 17256.910000 1.5.2. Разделим полученную сумму на число элементов 17256.91000 / 26 = 663.72731 1.5.3. Вычтем из последнего числа квадрат величины M x получим значение для S x 2 S x 2 = 663.72731 - 25.75000 2 = 663.72731 - 663.06250 = 0.66481 1.6. Вычислим значение S y 2 по формуле (1.6.) . 1.6.1. Сложим последовательно все элементы 5-го столбца таблицы 1 948.64000 + 864.36000 + ... + 948.64000 = 24191.840000 1.6.2. Разделим полученную сумму на число элементов 24191.84000 / 26 = 930.45538 1.6.3. Вычтем из последнего числа квадрат величины M y получим значение для S y 2 S y 2 = 930.45538 - 30.50000 2 = 930.45538 - 930.25000 = 0.20538 1.7. Вычислим произведение величин S x 2 и S y 2 . S x 2 S y 2 = 0.66481 0.20538 = 0.136541 1.8. Извлечем и последнего числа квадратный корень, получим значение S x S y . S x S y = 0.36951 1.9. Вычислим значение коэффициента корреляции по формуле (1.4.) . R = (785.10885 - 25.75000 30.50000) / 0.36951 = (785.10885 - 785.37500) / 0.36951 = -0.72028 ОТВЕТ: R x,y = -0.720279 2. Проверяем значимость коэффициента корреляции (проверяем гипотезу зависимости).Поскольку оценка коэффициента корреляции вычислена на конечной выборке, и поэтому может отклоняться от своего генерального значения,
необходимо проверить значимость коэффициента корреляции. Проверка производится с помощью t
-критерия:
Случайная величина t следует t -распределению Стьюдента и по таблице t -распределения необходимо найти критическое значение критерия (t кр.α) при заданном уровне значимости α . Если вычисленное по формуле (2.1) t по модулю окажется меньше чем t кр.α , то зависимости между случайными величинами X и Y нет. В противном случае, экспериментальные данные не противоречат гипотезе о зависимости случайных величин. 2.1. Вычислим значение t -критерия по формуле (2.1) получим:
2.2. Определим по таблице t -распределения критическое значение параметра t кр.α Искомое значение t
кр.α располагается на пересечении строки соответствующей числу степеней свободы
и столбца соответствующего заданному уровню значимости α
. Таблица 2 t -распределение
2.2. Сравним абсолютное значение t -критерия и t кр.α Абсолютное значение t -критерия не меньше критического t = 5.08680, t кр.α = 2.064, следовательно экспериментальные данные, с вероятностью 0.95 (1 - α ), не противоречат гипотезе о зависимости случайных величин X и Y. 3. Вычисляем коэффициенты уравнения линейной регрессии.Уравнение линейной регрессии представляет собой уравнение прямой, аппроксимирующей (приблизительно описывающей) зависимость между случайными величинами X и Y. Если считать, что величина X свободная, а Y зависимая от Х, то уравнение регрессии запишется следующим образом Y = a + b X (3.1), где:
Рассчитанный по формуле (3.2) коэффициент b называют коэффициентом линейной регрессии. В некоторых источниках a называют постоянным коэффициентом регрессии и b соответственно переменным. Погрешности предсказания Y по заданному значению X вычисляются по формулам: Величину σ y/x (формула 3.4) еще называют остаточным средним квадратическим отклонением , оно характеризует уход величины Y от линии регрессии, описываемой уравнением (3.1), при фиксированном (заданном) значении X. | . |
S y / S x = 0.55582
3.3 Вычислим коэффициент b по формуле (3.2)
b = -0.72028 0.55582 = -0.40035
3.4 Вычислим коэффициент a по формуле (3.3)
a = 30.50000 - (-0.40035 25.75000) = 40.80894
3.5 Оценим погрешности уравнения регрессии .
3.5.1 Извлечем из S y 2 квадратный корень получим:
3.5.4 Вычислим относительную погрешность по формуле (3.5)
δ y/x = (0.31437 / 30.50000)100% = 1.03073%
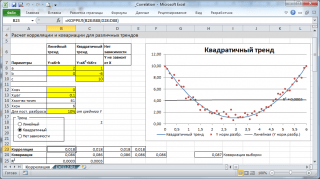
4. Строим диаграмму рассеяния (корреляционное поле) и график линии регрессии.
Диаграмма рассеяния - это графическое изображение соответствующих пар (x k , y k ) в виде точек плоскости, в прямоугольных координатах с осями X и Y. Корреляционное поле является одним из графических представлений связанной (парной) выборки. В той же системе координат строится и график линии регрессии. Следует тщательно выбрать масштабы и начальные точки на осях, чтобы диаграмма была максимально наглядной.4.1. Находим минимальный и максимальный элемент выборки X это 18-й и 15-й элементы соответственно, x min = 22.10000 и x max = 26.60000.
4.2. Находим минимальный и максимальный элемент выборки Y это 2-й и 18-й элементы соответственно, y min = 29.40000 и y max = 31.60000.
4.3. На оси абсцисс выбираем начальную точку чуть левее точки x 18 = 22.10000, и такой масштаб, чтобы на оси поместилась точка x 15 = 26.60000 и отчетливо различались остальные точки.
4.4. На оси ординат выбираем начальную точку чуть левее точки y 2 = 29.40000, и такой масштаб, чтобы на оси поместилась точка y 18 = 31.60000 и отчетливо различались остальные точки.
4.5. На оси абсцисс размещаем значения x k , а на оси ординат значения y k .
4.6. Наносим точки (x 1 , y 1 ), (x 2 , y 2 ),…,(x 26 , y 26 ) на координатную плоскость. Получаем диаграмму рассеяния (корреляционное поле), изображенное на рисунке ниже.
4.7. Начертим линию регрессии.
Для этого найдем две различные точки с координатами (x r1 , y r1) и (x r2 , y r2) удовлетворяющие уравнению (3.6), нанесем их на координатную плоскость и проведем через них прямую. В качестве абсциссы первой точки возьмем значение x min = 22.10000. Подставим значение x min в уравнение (3.6), получим ординату первой точки. Таким образом имеем точку с координатами (22.10000, 31.96127). Аналогичным образом получим координаты второй точки, положив в качестве абсциссы значение x max = 26.60000. Вторая точка будет: (26.60000, 30.15970).
Линия регрессии показана на рисунке ниже красным цветом
Обратите внимание, что линия регрессии всегда проходит через точку средних значений величин Х и Y, т.е. с координатами (M x , M y).
Вычислим коэффициент корреляции и ковариацию для разных типов взаимосвязей случайных величин.
Коэффициент корреляции (критерий корреляции Пирсона, англ. Pearson Product Moment correlation coefficient) определяет степень линейной взаимосвязи между случайными величинами.
Как следует из определения, для вычисления коэффициента корреляции требуется знать распределение случайных величин Х и Y. Если распределения неизвестны, то для оценки коэффициента корреляции используется выборочный коэффициент корреляции r (еще он обозначается как R xy или r xy ) :

где S x – стандартное отклонение выборки случайной величины х, вычисляемое по формуле:

Как видно из формулы для расчета корреляции , знаменатель (произведение стандартных отклонений) просто нормирует числитель таким образом, что корреляция оказывается безразмерным числом от -1 до 1. Корреляция и ковариация предоставляют одну и туже информацию (если известны стандартные отклонения ), но корреляцией удобнее пользоваться, т.к. она является безразмерной величиной.
Рассчитать коэффициент корреляции и ковариацию выборки в MS EXCEL не представляет труда, так как для этого имеются специальные функции КОРРЕЛ() и КОВАР() . Гораздо сложнее разобраться, как интерпретировать полученные значения, большая часть статьи посвящена именно этому.
Теоретическое отступление
Напомним, что корреляционной связью называют статистическую связь, состоящую в том, что различным значениям одной переменной соответствуют различные средние значения другой (с изменением значения Х среднее значение Y изменяется закономерным образом). Предполагается, что обе переменные Х и Y являются случайными величинами и имеют некий случайный разброс относительно их среднего значения .
Примечание . Если случайную природу имеет только одна переменная, например, Y, а значения другой являются детерминированными (задаваемыми исследователем), то можно говорить только о регрессии.
Таким образом, например, при исследовании зависимости среднегодовой температуры нельзя говорить о корреляции температуры и года наблюдения и, соответственно, применять показатели корреляции с соответствующей их интерпретацией.
Корреляционная связь между переменными может возникнуть несколькими путями:
- Наличие причинной зависимости между переменными. Например, количество инвестиций в научные исследования (переменная Х) и количество полученных патентов (Y). Первая переменная выступает как независимая переменная (фактор) , вторая - зависимая переменная (результат) . Необходимо помнить, что зависимость величин обуславливает наличие корреляционной связи между ними, но не наоборот.
- Наличие сопряженности (общей причины). Например, с ростом организации растет фонд оплаты труда (ФОТ) и затраты на аренду помещений. Очевидно, что неправильно предполагать, что аренда помещений зависит от ФОТ. Обе этих переменных во многих случаях линейно зависят от количества персонала.
- Взаимовлияние переменных (при изменении одной, вторая переменная изменяется, и наоборот). При таком подходе допустимы две постановки задачи; любая переменная может выступать как в роли независимой переменной и в роли зависимой.
Таким образом, показатель корреляции показывает, насколько сильна линейная взаимосвязь между двумя факторами (если она есть), а регрессия позволяет прогнозировать один фактор на основе другого.
Корреляция , как и любой другой статистический показатель, при правильном применении может быть полезной, но она также имеет и ограничения по использованию. Если показывает четко выраженную линейную зависимость или полное отсутствие взаимосвязи, то корреляция замечательно это отразит. Но, если данные показывают нелинейную взаимосвязь (например, квадратичную), наличие отдельных групп значений или выбросов, то вычисленное значение коэффициента корреляции может ввести в заблуждение (см. файл примера ).
Корреляция близкая к 1 или -1 (т.е. близкая по модулю к 1) показывает сильную линейную взаимосвязь переменных, значение близкое к 0 показывает отсутствие взаимосвязи. Положительная корреляция означает, что с ростом одного показателя другой в среднем увеличивается, а при отрицательной – уменьшается.
Для вычисления коэффициента корреляции требуется, чтобы сопоставляемые переменные удовлетворяли следующим условиям:
- количество переменных должно быть равно двум;
- переменные должны быть количественными (например, частота, вес, цена). Вычисленное среднее значение этих переменных имеет понятный смысл: средняя цена или средний вес пациента. В отличие от количественных, качественные (номинальные) переменные принимают значения лишь из конечного набора категорий (например, пол или группа крови). Этим значениям условно сопоставлены числовые значения (например, женский пол – 1, а мужской – 2). Понятно, что в этом случае вычисление среднего значения , которое требуется для нахождения корреляции , некорректно, а значит некорректно и вычисление самой корреляции ;
- переменные должны быть случайными величинами и иметь .
Двумерные данные могут иметь различную структуру. Для работы с некоторыми из них требуются определенные подходы:
- Для данных с нелинейной связью корреляцию нужно использовать с осторожностью. Для некоторых задач бывает полезно преобразовать одну или обе переменных так, чтобы получить линейную взаимосвязь (для этого требуется сделать предположение о виде нелинейной связи, чтобы предложить нужный тип преобразования).
- С помощью диаграммы рассеяния у некоторых данных можно наблюдать неравную вариацию (разброс). Проблема неодинаковой вариации состоит в том, что места с высокой вариацией не только предоставляют наименее точную информацию, но и оказывают наибольшее влияние при расчете статистических показателей. Эту проблему также часто решают с помощью преобразования данных, например, с помощью логарифмирования.
- У некоторых данных можно наблюдать разделение на группы (clustering), что может свидетельствовать о необходимости разделения совокупности на части.
- Выброс (резко отклоняющееся значение) может исказить вычисленное значение коэффициента корреляции. Выброс может быть причиной случайности, ошибки при сборе данных или могут действительно отражать некую особенность взаимосвязи. Так как выброс сильно отклоняется от среднего значения, то он вносит большой вклад при расчете показателя. Часто расчет статистических показателей производят с и без учета выбросов.
Использование MS EXCEL для расчета корреляции
В качестве примера возьмем 2 переменные Х и Y и, соответственно, выборку состоящую из нескольких пар значений (Х i ; Y i). Для наглядности построим .
Примечание : Подробнее о построении диаграмм см. статью . В файле примера для построения диаграммы рассеяния использована , т.к. мы здесь отступили от требования случайности переменной Х (это упрощает генерацию различных типов взаимосвязей: построение трендов и заданный разброс). В случае реальных данных необходимо использовать диаграмму типа Точечная (см. ниже).
Расчеты корреляции проведем для различных случаев взаимосвязи между переменными: линейной, квадратичной и при отсутствии связи .
Примечание : В файле примера можно задать параметры линейного тренда (наклон, пересечение с осью Y) и степень разброса относительно этой линии тренда. Также можно настроить параметры квадратичной зависимости.
В файле примера для построения диаграммы рассеяния в случае отсутствия зависимости переменных использована диаграмма типа Точечная. В этом случае точки на диаграмме располагаются в виде облака.

Примечание : Обратите внимание, что изменяя масштаб диаграммы по вертикальной или горизонтальной оси, облаку точек можно придать вид вертикальной или горизонтальной линии. Понятно, что при этом переменные останутся независимыми.
Как было сказано выше, для расчета коэффициента корреляции в MS EXCEL существует функций КОРРЕЛ() . Также можно воспользоваться аналогичной функцией PEARSON() , которая возвращает тот же результат.
Для того, чтобы удостовериться, что вычисления корреляции производятся функцией КОРРЕЛ() по вышеуказанным формулам, в файле примера приведено вычисление корреляции с помощью более подробных формул:
=КОВАРИАЦИЯ.Г(B28:B88;D28:D88)/СТАНДОТКЛОН.Г(B28:B88)/СТАНДОТКЛОН.Г(D28:D88)
=КОВАРИАЦИЯ.В(B28:B88;D28:D88)/СТАНДОТКЛОН.В(B28:B88)/СТАНДОТКЛОН.В(D28:D88)
Примечание : Квадрат коэффициента корреляции r равен коэффициенту детерминации R2, который вычисляется при построении линии регрессии с помощью функции КВПИРСОН() . Значение R2 также можно вывести на диаграмме рассеяния , построив линейный тренд с помощью стандартного функционала MS EXCEL (выделите диаграмму, выберите вкладку Макет , затем в группе Анализ нажмите кнопку Линия тренда и выберите Линейное приближение ). Подробнее о построении линии тренда см., например, в .
Использование MS EXCEL для расчета ковариации
Ковариация близка по смыслу с (также является мерой разброса) с тем отличием, что она определена для 2-х переменных, а дисперсия - для одной. Поэтому, cov(x;x)=VAR(x).

Для вычисления ковариации в MS EXCEL (начиная с версии 2010 года) используются функции КОВАРИАЦИЯ.Г() и КОВАРИАЦИЯ.В() . В первом случае формула для вычисления аналогична вышеуказанной (окончание .Г обозначает Генеральная совокупность ), во втором – вместо множителя 1/n используется 1/(n-1), т.е. окончание .В обозначает Выборка .
Примечание : Функция КОВАР() , которая присутствует в MS EXCEL более ранних версий, аналогична функции КОВАРИАЦИЯ.Г() .
Примечание : Функции КОРРЕЛ() и КОВАР() в английской версии представлены как CORREL и COVAR. Функции КОВАРИАЦИЯ.Г() и КОВАРИАЦИЯ.В() как COVARIANCE.P и COVARIANCE.S.
Дополнительные формулы для расчета ковариации :
=СУММПРОИЗВ(B28:B88-СРЗНАЧ(B28:B88);(D28:D88-СРЗНАЧ(D28:D88)))/СЧЁТ(D28:D88)
=СУММПРОИЗВ(B28:B88-СРЗНАЧ(B28:B88);(D28:D88))/СЧЁТ(D28:D88)
=СУММПРОИЗВ(B28:B88;D28:D88)/СЧЁТ(D28:D88)-СРЗНАЧ(B28:B88)*СРЗНАЧ(D28:D88)
Эти формулы используют свойство ковариации :

Если переменные x и y независимые, то их ковариация равна 0. Если переменные не являются независимыми, то дисперсия их суммы равна:
VAR(x+y)= VAR(x)+ VAR(y)+2COV(x;y)
А дисперсия их разности равна
VAR(x-y)= VAR(x)+ VAR(y)-2COV(x;y)
Оценка статистической значимости коэффициента корреляции
Для того чтобы проверить гипотезу, мы должны знать распределение случайной величины, т.е. коэффициента корреляции r. Обычно, проверку гипотезы осуществляют не для r, а для случайной величины t r:

которая имеет с n-2 степенями свободы.
Если вычисленное значение случайной величины |t r | больше, чем критическое значение t α,n-2 (α- заданный ), то нулевую гипотезу отклоняют (взаимосвязь величин является статистически значимой).

Надстройка Пакет анализа
В для вычисления ковариации и корреляции имеются одноименные инструменты анализа .

После вызова инструмента появляется диалоговое окно, которое содержит следующие поля:

- Входной интервал : нужно ввести ссылку на диапазон с исходными данными для 2-х переменных
- Группирование : как правило, исходные данные вводятся в 2 столбца
- Метки в первой строке : если установлена галочка, то Входной интервал должен содержать заголовки столбцов. Рекомендуется устанавливать галочку, чтобы результат работы Надстройки содержал информативные столбцы
- Выходной интервал : диапазон ячеек, куда будут помещены результаты вычислений. Достаточно указать левую верхнюю ячейку этого диапазона.
Надстройка возвращает вычисленные значения корреляции и ковариации (для ковариации также вычисляются дисперсии обоих случайных величин).

ЛАБОРАТОРНАЯ РАБОТА
КОРРЕЛЯЦИОННЫЙ АНАЛИЗ В EXCEL
1.1 Корреляционный анализ в MS Excel
Корреляционный анализ состоит в определении степени связи между двумя случайными величинами X и Y. В качестве меры такой связи используется коэффициент корреляции. Коэффициент корреляции оценивается по выборке объема п связанных пар наблюдений (x i , y i) из совместной генеральной совокупности X и Y. Для оценки степени взаимосвязи величин X и Y, измеренных в количественных шкалах, используетсякоэффициент линейной корреляции (коэффициент Пирсона), предполагающий, что выборки X и Y распределены по нормальному закону.
Коэффициент корреляции изменяется от -1 (строгая обратная линейная зависимость) до 1 (строгая прямая пропорциональная зависимость). При значении 0 линейной зависимости между двумя выборками нет.
Общая классификация корреляционных связей (по Ивантер Э.В., Коросову А.В., 1992):
Существует несколько типов коэффициентов корреляции, что зависит от переменных Х иY, которые могут быть измерены в разных шкалах. Именно этот факт и определяет выбор соответствующего коэффициента корреляции (см. табл. 13):
В MS Excel для вычисления парных коэффициентов линейной корреляции используется специальная функция КОРРЕЛ (массив1; массив2),
|
№ испытуемых | ||
Пример 1: 10 школьникам были даны тесты на наглядно-образное и вербальное мышление. Измерялось среднее время решения заданий теста в секундах. Исследователя интересует вопрос: существует ли взаимосвязь между временем решения этих задач? Переменная X - обозначает среднее время решения наглядно-образных, а переменная Y- среднее время решения вербальных заданий тестов.
Р ешение:
Для выявления степени взаимосвязи,
прежде всего, необходимо ввести данные
в таблицу MS Excel (см. табл., рис. 1). Затем
вычисляется значение коэффициента
корреляции. Для этого курсор установите
в ячейку C1. На панели инструментов
нажмите кнопку Вставка функции (fx).
ешение:
Для выявления степени взаимосвязи,
прежде всего, необходимо ввести данные
в таблицу MS Excel (см. табл., рис. 1). Затем
вычисляется значение коэффициента
корреляции. Для этого курсор установите
в ячейку C1. На панели инструментов
нажмите кнопку Вставка функции (fx).
В появившемся диалоговом окне Мастер функций выберите категорию Статистические и функциюКОРРЕЛ , после чего нажмите кнопку ОК. Указателем мыши введите диапазон данных выборки Х в поле массив1 (А1:А10). В поле массив2 введите диапазон данных выборки У (В1:В10). Нажмите кнопку ОК. В ячейке С1 появится значение коэффициента корреляции - 0,54119. Далее необходимо посмотреть на абсолютное число коэффициента корреляции и определить тип связи (тесная, слабая, средняя и т.д.)
Рис. 1. Результаты вычисления коэффициента корреляции
Таким образом, связь между временем решения наглядно-образных и вербальных заданий теста не доказана.
Задание 1. Имеются данные по 20 сельскохозяйственным хозяйствам. Найтикоэффициент корреляции между величинами урожайности зерновых культур и качеством земли и оценить его значимость. Данные приведены в таблице.
Таблица 2. Зависимость урожайности зерновых культур от качества земли
|
Номер хозяйства |
Качество земли, балл |
Урожайность, ц/га |
Задание 2. Определите, имеется ли связь между временем работы спортивного тренажера для фитнеса (тыс. часов) и стоимость его ремонта (тыс. руб.):
|
Время работа тренажера (тыс. часов) |
Стоимость ремонта (тыс. руб.) |
1.2 Множественная корреляция в MS Excel
При большом числе наблюдений, когда коэффициенты корреляции необходимо последовательно вычислять для нескольких выборок, для удобства получаемые коэффициенты сводят в таблицы, называемые корреляционными матрицами .
Корреляционная матрица - это квадратная таблица, в которой на пересечении соответствующих строк и столбцов находятся коэффициент корреляции между соответствующими параметрами.
В MS Excel для вычисления корреляционных матриц используется процедура Корреляция из пакета Анализ данных. Процедура позволяет получить корреляционную матрицу, содержащую коэффициенты корреляции между различными параметрами.
Для реализации процедуры необходимо:
1. выполнить команду Сервис - Анализ данных ;
2. в появившемся списке Инструменты анализа выбрать строку Корреляция и нажать кнопку ОК ;
3. в появившемся диалоговом окне указать Входной интервал , то есть ввести ссылку на ячейки, содержащие анализируемые данные. Входной интервал должен содержать не менее двух столбцов.
4. в разделе Группировка переключатель установить в соответствии с введенными данными (по столбцам или по строкам);
5. указать выходной интервал , то есть ввести ссылку на ячейку, начиная с которой будут показаны результаты анализа. Размер выходного диапазона будет определен автоматически, и на экран будет выведено сообщение в случае возможного наложения выходного диапазона на исходные данные. Нажать кнопку ОК .
В выходной диапазон будет выведена корреляционная матрица, в которой на пересечении каждых строки и столбца находится коэффициент корреляции между соответствующими параметрами. Ячейки выходного диапазона, имеющие совпадающие координаты строк и столбцов, содержат значение 1, так как каждый столбец во входном диапазоне полностью коррелирует сам с собой
Пример 2. Имеются ежемесячные данные наблюдений за состоянием погоды и посещаемостью музеев и парков (см. табл. 3). Необходимо определить, существует ли взаимосвязь между состоянием погоды и посещаемостью музеев и парков.
Таблица 3. Результаты наблюдений
|
Число ясных дней |
Количество посетителей музея |
Количество посетителей парка |
Решение . Для выполнения корреляционного анализа введите в диапазон A1:G3 исходные данные (рис. 2). Затем в меню Сервис выберите пункт Анализ данных и далее укажите строку Корреляция . В появившемся диалоговом окне укажите Входной интервал (А2:С7). Укажите, что данные рассматриваются по столбцам. Укажите выходной диапазон (Е1) и нажмите кнопку ОК .
На рис. 33 видно, что корреляция между состоянием погоды и посещаемостью музея равна -0,92, а между состоянием погоды и посещаемостью парка - 0,97, между посещаемостью парка и музея - 0,92.
Таким образом, в результате анализа выявлены зависимости: сильная степень обратной линейной взаимосвязи между посещаемостью музея и количеством солнечных дней и практически линейная (очень сильная прямая) связь между посещаемостью парка и состоянием погоды. Между посещаемостью музея и парка имеется сильная обратная взаимосвязь.

Рис. 2. Результаты вычисления корреляционной матрицы из примера 2
Задание 3 . 10 менеджеров оценивались по методике экспертных оценок психологических характеристик личности руководителя. 15 экспертов производили оценку каждой психологической характеристики по пятибальной системе (см. табл. 4). Психолога интересует вопрос, в какой взаимосвязи находятся эти характеристики руководителя между собой.
Таблица 4. Результаты исследования
|
Испытуемые п/п |
тактичность |
требовательность |
критичность |
По территориям региона приводятся данные за 200Х г.
| Номер региона | Среднедушевой прожиточный минимум в день одного трудоспособного, руб., х | Среднедневная заработная плата, руб., у |
|---|---|---|
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
Задание:
1. Постройте поле корреляции и сформулируйте гипотезу о форме связи.
2. Рассчитайте параметры уравнения линейной регрессии
4. Дайте с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
7. Рассчитайте прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости .
Решение:
Решим данную задачу с помощью Excel.
1. Сопоставив имеющиеся данные х и у, например, ранжировав их в порядке возрастания фактора х, можно наблюдать наличие прямой зависимости между признаками, когда увеличение среднедушевого прожиточного минимума увеличивает среднедневную заработную плату. Исходя из этого, можно сделать предположение, что связь между признаками прямая и её можно описать уравнением прямой. Этот же вывод подтверждается и на основе графического анализа.
Чтобы построить поле корреляции можно воспользоваться ППП Excel. Введите исходные данные в последовательности: сначала х, затем у.
Выделите область ячеек, содержащую данные.
Затем выберете: Вставка / Точечная диаграмма / Точечная с маркерами как показано на рисунке 1.

Рисунок 1 Построение поля корреляции
Анализ поля корреляции показывает наличие близкой к прямолинейной зависимости, так как точки расположены практически по прямой линии.
2. Для расчёта параметров уравнения линейной регрессии
воспользуемся встроенной статистической функцией ЛИНЕЙН
.
Для этого:
1) Откройте существующий файл, содержащий анализируемые данные;
2) Выделите область пустых ячеек 5×2 (5 строк, 2 столбца) для вывода результатов регрессионной статистики.
3) Активизируйте Мастер функций
: в главном меню выберете Формулы / Вставить функцию
.
4) В окне Категория
выберете Статистические
, в окне функция - ЛИНЕЙН
. Щёлкните по кнопке ОК
как показано на Рисунке 2;

Рисунок 2 Диалоговое окно «Мастер функций»
5) Заполните аргументы функции:
Известные значения у
Известные значения х
Константа - логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении; если Константа = 1, то свободный член рассчитывается обычным образом, если Константа = 0, то свободный член равен 0;
Статистика - логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если Статистика = 0, то выводятся только оценки параметров уравнения.
Щёлкните по кнопке ОК ;

Рисунок 3 Диалоговое окно аргументов функции ЛИНЕЙН
6) В левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
| Значение коэффициента b | Значение коэффициента a |
| Стандартная ошибка b | Стандартная ошибка a |
| Стандартная ошибка y | |
| F-статистика | |
| Регрессионная сумма квадратов
|

Рисунок 4 Результат вычисления функции ЛИНЕЙН
Получили уровнение регрессии:
Делаем вывод: С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.
Означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х - среднедушевого прожиточного минимума, а 48% - действием других факторов, не включённых в модель.
По вычисленному коэффициенту детерминации можно рассчитать коэффициент корреляции: ![]() .
.
Связь оценивается как тесная.
4. С помощью среднего (общего) коэффициента эластичности определим силу влияния фактора на результат.
Для уравнения прямой средний (общий) коэффициент эластичности определим по формуле:

Средние значения найдём, выделив область ячеек со значениями х, и выберем Формулы / Автосумма / Среднее , и то же самое произведём со значениями у.

Рисунок 5 Расчёт средних значений функции и аргумент
Таким образом, при изменении среднедушевого прожиточного минимума на 1% от своего среднего значения среднедневная заработная плата изменится в среднем на 0,51%.
С помощью инструмента анализа данных Регрессия
можно получить:
- результаты регрессионной статистики,
- результаты дисперсионного анализа,
- результаты доверительных интервалов,
- остатки и графики подбора линии регрессии,
- остатки и нормальную вероятность.
Порядок действий следующий:
1) проверьте доступ к Пакету анализа . В главном меню последовательно выберите: Файл/Параметры/Надстройки .
2) В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
3) В окне Надстройки установите флажок Пакет анализа , а затем нажмите кнопку ОК .
Если Пакет анализа отсутствует в списке поля Доступные надстройки , нажмите кнопку Обзор , чтобы выполнить поиск.
Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да , чтобы установить его.
4) В главном меню последовательно выберите: Данные / Анализ данных / Инструменты анализа / Регрессия , а затем нажмите кнопку ОК .
5) Заполните диалоговое окно ввода данных и параметров вывода:
Входной интервал Y - диапазон, содержащий данные результативного признака;
Входной интервал X - диапазон, содержащий данные факторного признака;
Метки - флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Константа - ноль - флажок, указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал - достаточно указать левую верхнюю ячейку будущего диапазона;
6) Новый рабочий лист - можно задать произвольное имя нового листа.
Затем нажмите кнопку ОК .

Рисунок 6 Диалоговое окно ввода параметров инструмента Регрессия
Результаты регрессионного анализа для данных задачи представлены на рисунке 7.

Рисунок 7 Результат применения инструмента регрессия
5. Оценим с помощью средней ошибки аппроксимации качество уравнений. Воспользуемся результатами регрессионного анализа представленного на Рисунке 8.

Рисунок 8 Результат применения инструмента регрессия «Вывод остатка»
Составим новую таблицу как показано на рисунке 9. В графе С рассчитаем относительную ошибку аппроксимации по формуле:
![]()

Рисунок 9 Расчёт средней ошибки аппроксимации
Средняя ошибка аппроксимации рассчитывается по формуле:

Качество построенной модели оценивается как хорошее, так как не превышает 8 - 10%.
6. Из таблицы с регрессионной статистикой (Рисунок 4) выпишем фактическое значение F-критерия Фишера: ![]()
Поскольку ![]() при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
8. Оценку статистической значимости параметров регрессии проведём с помощью t-статистики Стьюдента и путём расчёта доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н 0 о статистически незначимом отличии показателей от нуля:
![]() .
.
![]() для числа степеней свободы
для числа степеней свободы
На рисунке 7 имеются фактические значения t-статистики:
t-критерий для коэффициента корреляции можно рассчитать двумя способами:
I способ:
где  - случайная ошибка коэффициента корреляции.
- случайная ошибка коэффициента корреляции.
Данные для расчёта возьмём из таблицы на Рисунке 7.

II способ:
Фактические значения t-статистики превосходят табличные значения:
Поэтому гипотеза Н 0 отклоняется, то есть параметры регрессии и коэффициент корреляции не случайно отличаются от нуля, а статистически значимы.
Доверительный интервал для параметра a определяется как
![]()
Для параметра a 95%-ные границы как показано на рисунке 7 составили:
Доверительный интервал для коэффициента регрессии определяется как
![]()
Для коэффициента регрессии b 95%-ные границы как показано на рисунке 7 составили:
![]()
Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью ![]() параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
7. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение прожиточного минимума составит:
Тогда прогнозное значение прожиточного минимума составит:
Ошибку прогноза рассчитаем по формуле:

где ![]()
Дисперсию посчитаем также с помощью ППП Excel. Для этого:
1) Активизируйте Мастер функций : в главном меню выберете Формулы / Вставить функцию .
3) Заполните диапазон, содержащий числовые данные факторного признака. Нажмите ОК .

Рисунок 10 Расчёт дисперсии
Получили значение дисперсии ![]()
Для подсчёта остаточной дисперсии на одну степень свободы воспользуемся результатами дисперсионного анализа как показано на Рисунке 7.

Доверительные интервалы прогноза индивидуальных значений у при с вероятностью 0,95 определяются выражением:
![]()
Интервал достаточно широк, прежде всего, за счёт малого объёма наблюдений. В целом выполненный прогноз среднемесячной заработной платы оказался надёжным.
Условие задачи взято из: Практикум по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. - М.: Финансы и статистика, 2003. - 192 с.: ил.




Популярное
- Огэ английский язык тренировочные тесты
- Как подготовиться к УЗИ почек: полезные советы
- К чему снится тюлень мужчинам, женщинам и детям?
- Вкусные крабовые салаты с грибами и кукурузой Крабовый салат с грибами и сыром
- Салат с курицей и огурцом
- Похищение человека видеть во сне
- Молитвы о примирении враждующих после сильной ссоры супругов, родственников, друзей
- «Пошли в лобовую атаку»: как конгресс заставил Дональда Трампа подписать закон о санкциях против России
- Существовал ил на самом деле пророк Даниил?
- БГУ. История БГУ. Белорусский государственный университет Легко ли учиться в БГУ